

Modify images via text
Getting started
This example shows how to use qwen-image-2.0-pro to generate two edited images from three input images and a prompt.
Input prompt: The girl in Image 1 wears the black dress from Image 2 and sits in the pose from Image 3.
| Input image 1 | Input image 2 | Input image 3 | Output images (multiple images) | |
|---|---|---|---|---|
 |  | 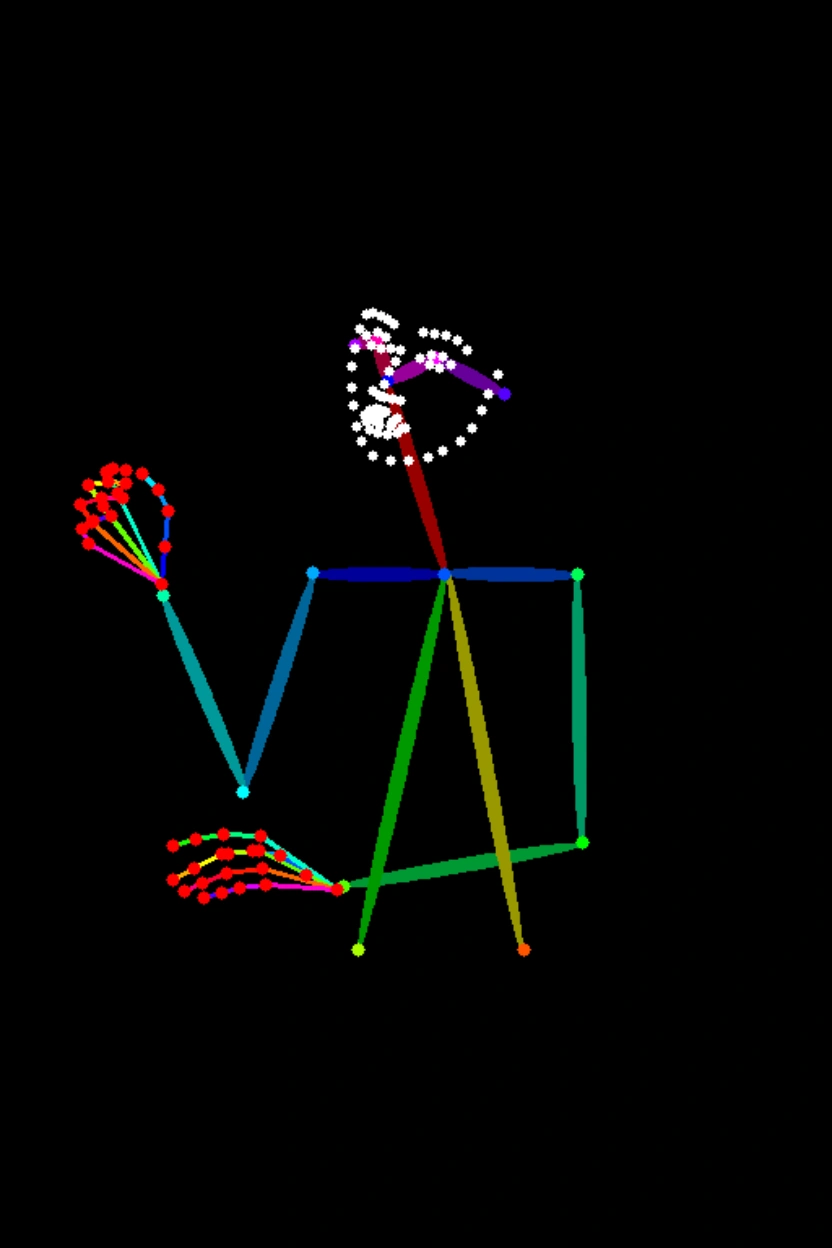 |  |  |
qwen-image-2.0, qwen-image-edit-max, and qwen-image-edit-plus series can generate one to six images. qwen-image-edit can generate only one image. The URLs for the generated images are valid for 24 hours. Download the images to your local device promptly.
- Python
- Java
- curl
Response example
Response example
Download images to your local device
Download images to your local device
- Python
- Java
Input instructions
Input images (messages)
The messages parameter is an array that must contain a single object. This object must include the role and content properties. The role property must be set to user. The content property must include both image (one to three images) and text (one editing instruction).
The input images must meet the following requirements:
-
The supported image formats are JPG, JPEG, PNG, BMP, TIFF, WEBP, and GIF.
The output image is in PNG format. For animated GIFs, only the first frame is processed.
- For best results, the image resolution should be between 384 and 3072 pixels for both width and height. A low resolution may result in a blurry output, while a high resolution increases processing time.
- The size of a single image file cannot exceed 10 MB.
Image input order
| Input image 1 | Input image 2 | Output image | |
|---|---|---|---|
 |  |  |  |
Image input methods
Public URL
- You can provide a publicly accessible image URL that supports the HTTP or HTTPS protocol.
- Example value:
https://xxxx/img.png.
data:<mime_type>;base64,<base64_data>.
<mime_type>: The media type of the image, which must correspond to the file format.<base64_data>: The Base64-encoded string of the file.- Example value:
data:image/jpeg;base64,GDU7MtCZz...(The example is truncated for demonstration purposes.)
More parameters
Adjust the generation results using the following optional parameters:
-
n: The number of images to generate. The default value is 1. The qwen-image-2.0, qwen-image-edit-max, and qwen-image-edit-plus series of models support generating one to six images. The
qwen-image-editmodel supports generating only one image. - negative_prompt: Describes content to exclude from the image, such as "blur" or "extra fingers". This parameter helps optimize the quality of the generated image.
-
watermark: Specifies whether to add a "Qwen-Image" watermark to the bottom-right corner of the image. The default value is
false. -
seed: The random number seed. The value must be an integer from
[0, 2147483647]. If this parameter is not specified, the algorithm generates a random number to use as the seed. Using the same seed value helps ensure consistent generation results.
- size: The resolution of the output image. The format is
width*height, such as"1024*2048". For the qwen-image-2.0 series models, you can set the width and height freely. The total pixels of the output image must be between 512 x 512 and 2048 x 2048. By default, the resolution is the same as the input image (the last image if multiple are provided). For the qwen-image-edit-max and qwen-image-edit-plus series models, the width and height can range from 512 to 2048 pixels. By default, the output image has a resolution close to1024*1024and an aspect ratio similar to the original image. - prompt_extend: Enables or disables the prompt rewriting feature. The default value is
true. If enabled, the model optimizes the prompt. This feature can significantly improve the results for simple or less descriptive prompts.
Overview
Multi-image fusion
| Input image 1 | Input image 2 | Input image 3 | Output image |
|---|---|---|---|
 |  |  |  |
Subject consistency
| Input image | Output image 1 | Output image 2 |
|---|---|---|
 |  |  |
 |  |  |
Sketch creation
| Input image | Output image | |
|---|---|---|
 |  |  |
Creative product generation
| Input image | Output image | ||
|---|---|---|---|
 |  |  |  |
 |  |  |
Generate image from depth map
| Input image | Output image | |
|---|---|---|
 |  |  |
Generate image from keypoints
| Input image | Output image | |
|---|---|---|
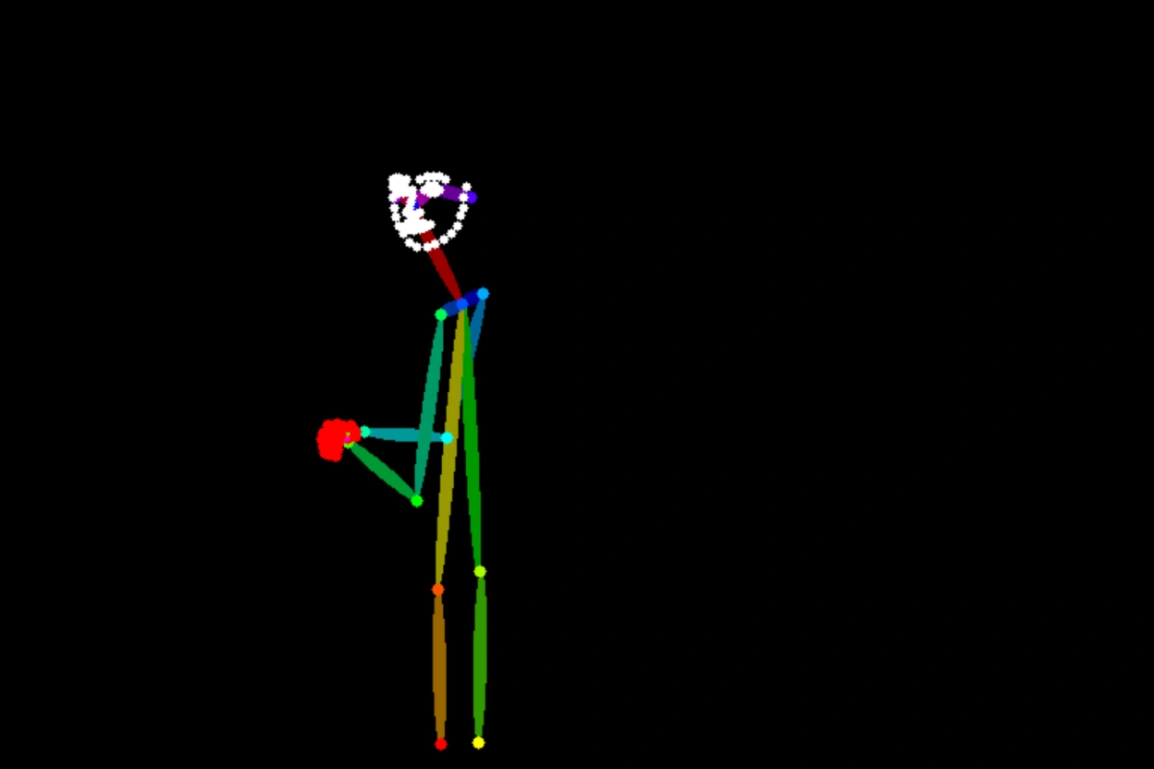 |  |  |
Text editing
| Input image | Output image | Input image | Output image |
|---|---|---|---|
 |  |  |  |
| Input image | Output image | ||
|---|---|---|---|
 |  |  |  |
 |  |  | |
 |  |  |
Add, delete, replace, and modify
| Input image | Output image | Input image | Output image |
|---|---|---|---|
 |  |  |  |
Viewpoint transformation
| Input image | Output image | Input image | Output image |
|---|---|---|---|
 |  |  |  |
 |  |  |  |
Old photo processing
| Input image | Output image |
|---|---|
 |  |
 |  |
Billing and rate limits
For free quota and pricing, see pricing.
For rate limits, see Rate limits.
Billing details:
- Billing is based on the number of successfully generated images. Failed model calls or processing errors do not incur fees or consume the free quota.
- You can enable the 'Free quota only' feature to avoid extra charges after your free quota is used up. For more information, see Free quota for new users.